吉林网站优化软件培训班
文章目录
- 📚FTL综述
- 📚映射管理
- 🐇映射的种类
- 🐇映射的基本原理
- 🐇HMB
- 🐇映射表写入
📚FTL综述
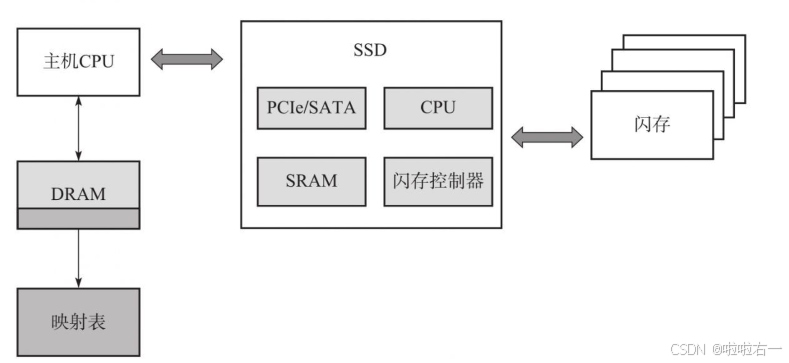
- 当SSD所使用的主控和闪存确定后,FTL算法的好坏将直接决定SSD在性能、可靠性、耐用性等方面的好坏,FTL可以说是SSD固件的核心。
- FTL(Flash Translation Layer,闪存转换层)用于完成主机逻辑地址空间到闪存物理地址空间的翻译,或者说是映射。
- SSD每把一笔用户逻辑数据写入闪存地址空间,便记录下该逻辑地址到物理地址的映射关系,下次主机想读取该数据时,固件根据这个映射便能从闪存中把这笔数据读上来然后返回给用户。
- 完成逻辑地址空间到物理地址空间的映射,这是FTL最原始也是最基本的功能。事实上,现在SSD中的FTL要做的事情还有很多,比如垃圾回收、磨损均衡、异常掉电处理等。
- 通过实现这些算法,FTL把SSD存储介质特性隐藏起来,使用户使用基于闪存的SSD像使用传统HDD一样,不用考虑存储介质特性。
- SSD使用的存储介质一般是NAND闪存,它具有如下特性。
- 闪存块需先擦除才能写入,不能覆盖写。
- 当写入一笔新的数据时,不能直接在老地方直接更改,必须写到一个新的位置。
- 因此,SSD的固件需要维护一张逻辑地址到物理地址的映射表,以跟踪每个逻辑块最新数据存储在闪存中的位置。另外,往一个新的位置写入数据,会导致老位置上的数据变成无效,这些数据就成为垃圾数据了。
- 垃圾数据会占用闪存空间,当闪存可用空间不足时,FTL需要做垃圾回收,即把若干个闪存块上的有效数据搬到某个新的闪存块,然后把这些闪存块擦除,得到可用的闪存块。
- 闪存块都是有一定寿命的。
- 每擦写一次闪存,都会对闪存块造成损,因此闪存块都是有寿命的。
- 闪存块的寿命用P/E Cycle(Program/Erase Cycle,编程/擦除次数)衡量。我们不能集中往某几个闪存块上写数据,不然这几个闪存块很快就会因PEC耗尽而死亡,变成坏块。
- FTL需要做磨损均衡(Wear Leveling),让数据的写入尽量均摊到SSD中的每个闪存块上,即让每个块损都差不多,从而保证 SSD具有最大的数据写入量。
- 存在读干扰问题。
- 每个闪存块可读的次数也是有限的,读得太多,上面的数据也会出错,这就是读干扰问题。
- FTL需要处理读干扰问题,当某个闪存块读的次数马上要达到一定阈值时,FTL需要把这些数据从该闪存块上搬走,从而避免数据出错。
- 存在数据保持问题。
- 由于电荷的流失,存储在闪存上的数据会丢失。这个时间长则十多年,短则几年甚至几个月。
- 如果SSD不上电,FTL对此也是毫无办法,但一旦上电,FTL就可对此进行处理,比如定期扫描闪存,发现是否存在数据保持问题,如果存在,则需要刷新数据——把数据从一个有问题的闪存块搬到新的闪存块,防患于未然。
- 存在坏块。
- 闪存天然就有坏块。另外,随着SSD的使用,也会产生新的坏块。
- 坏块出现的症状是擦写失败或者读失败(BCC不能纠正数据错误)。坏块管理也是FTL的一大任务。
- QLC 或者 TLC 可以配成 SLC来使用。
- SLC相较QLC或者TLC,具有更高的性能寿命和可靠性。
- 对追求突发性能的SSD来说,比如消费级SSD,它们的FTL会利用这个特性来改善 SSD 的突发写入性能;有的SSD还会利用SLC提高数据的可靠性。
- 闪存块需先擦除才能写入,不能覆盖写。
- FTL有Host-Based和Device-Based两种。
-
Host-Based:FTL的实现是在Host端的,用的是计算机的CPU和内存资源。使用 Host-Based FTL的 SSD,需要 SSD 厂商和 SSD 使用者深度合作完成,多为企业级产品。

-
Device-Based:FTL是在Device端实现的,用的是SSD上的控制器和RAM资源。FTL在设备固件里处于中间层,起着承上启下的作用——把前端主机的读写请求转换成对后端闪存的读写请求。(目前主流SSD都是Device-Based FTL)

-
📚映射管理
🐇映射的种类
-
⭐️块映射
- 以闪存块为映射粒度,一个用户逻辑块可以映射到任意一个闪存物理块,每个页在块中的偏移保持不变。如下图所示,用户空间划分成一个一个逻辑区域,每个逻辑区城大小和闪存块大小一样。
- 由于映射表只需存储块的映射,因此存储映射表所需空间小,但其性能差,尤其是小尺寸数据的写入性能,因为用户即使只更新一个逻辑页,也需要把整个物理块数据先读出来,然后改变逻辑页的数据,最后对整个块进行写入。
- 总体来说,块映射有好的连续大尺寸的读写性能,但小尺寸数据的写性能是非常糟糕的。

-
⭐️页映射
- 以闪存页为映射粒度,一个逻辑页可以映射到任意一个物理页中,因此每一个页都有一个对应的映射关系。
- 由于闪存页远比闪存块多(一个闪存块包含几百甚至几千个物理页),因此需要更多的空间来存储映射表。但它的性能更好,尤其体现在随机写上面。为追求性能,SSD一般都采用页映射。
- 如下图所示,用户空间被划分成一个一个的逻辑区域,每个逻辑区域大小和闪存页大小一样。在实际场景中,逻辑区域可能小于闪存页大小,一个闪存页可容纳若干个逻辑区域数据。

-
⭐️混合映射
- 混合映射是块映射和页映射的结合。一个逻辑块可以映射到任意一个物理块,但在块内采用页映射的方式,一个逻辑块中的逻辑页可以映射到对应物理块中的任意页。因此,它的映射表所需存储空间以及读写性能都是介于块映射和页映射之间的。
- 如下图所示,用户空间可划分成一个一个逻辑区域,逻辑区域大小和闪存块大小一样。每个逻辑块对应着一个闪存块,逻辑块又分成一个一个逻辑页,逻辑页和对应闪存块里面的闪存页任意对应。

-
⭐️不同映射之间的比较
- ps:当前主流SSD基本都是采用页映射

- ps:当前主流SSD基本都是采用页映射
🐇映射的基本原理
-
⭐️L2P映射
- 用户是通过LBA(Logical Block Address,逻辑块地址)访问SSD的,每个LBA代表一个逻辑块(大小一般为512B、4KB、8KB…),我们把用户访问 SSD的基本单元称为逻辑页(Logical Page)。
- 在SSD内部,主控以闪存页为基本单元读写闪存。我们称闪存页为物理页(Physical Page)。用户每写入一个逻辑页,SSD固件会找一个物理页把用户数据写入,并记录这个逻辑地址到物理地址的映射关系。
- 有了这个映射关系,下次用户需要读某个逻辑页时,SSD通过查找与该逻辑页对应的物理地址就知道从闪存的哪个位置把数据读取出来,如下图所示。

- SSD内部维护了一张逻辑页地址到物理页地址转换(Logical address To Physical address,L2P)的映射表。
- 用户每写入一个逻辑页,就会产生一个新的映射关系,这个映射关系会加入(第一次写)或者更改(覆盖写)映射表,以追踪该逻辑页最新数据所在的物理位置;当读取某个逻辑页时,SSD首先查找映射表中与该逻辑页对应的物理页,然后访问闪存并读取相应的用户数据。
- 由于内存页和逻辑页大小不同,一般前者大于后者,所以在实际场景中不会是一个逻辑页对应一个物理页,而是若干个逻辑页写在一个物理页:逻辑页其实是和子物理页一一对应的。
-
⭐️映射表大小
- 假设有一个256GB的SSD,以4KB大小的逻辑页为例,那么用户空间一共有64M(256GB/4KB)个逻辑页,也就意味着SSD需要有能容纳64M条映射关系的映射表。
- 映射表中的每个单元存储的是物理地址,假设用4B来表示,那么整个映射表的大小是256MB(64M×4B)。所以一般来说,映射表大小为SSD容量的千分之一(准确说是1/1024,前提是映射页大小为4KB,物理地址用4B表示)。
-
⭐️板载DRAM or 不带DRAM
-
对早期SSD以及现在的企业级SSD来说,上面都有板载DRAM,主要作用就是存储映射表。在SSD工作时,全部的或者绝大部分的映射表都可以缓存在 DRAM 中,这样固件就可以快速获得和更新映射关系。

-
但对消费级SSD或者移动存储设备(比如eMMC、UFS)来说,出于成本和功耗考虑,它们采用DRAM-less设计,即不带DRAM。它们一般采用多级映射。

- 如下图所示,一级映射表常驻SRAM,二级映射表就是L2P映射表,按映射块管理,它大部分存储在闪存中,小部分缓存在RAM中。
- 一级表存储这些映射块在闪存中的物理地址,由于它不是很大,所以一般可以完全放在RAM中。
- 经典的不带DRAM的FTL架构是DFTL(Demand-basedFTL),它算是后续所有DRAM-less FTL的鼻祖。

- DRAM是动态随机访问存储器,需要周期性刷新,容量大但速度较慢。
- SRAM是静态随机访问存储器,不需要刷新,速度快但容量较小。
- SSD处理读取命令时:
- 对带DRAM的SSD来说,只要查找DRAM当中的映射表,获取物理地址后再访问闪存就可得到用户数据,这期间只需要访问一次闪存。
- 对不带DRAM的SSD来说,它首先要看与该逻辑页对应的映射关系是否在SRAM内,如果在,那就直接根据映射关系读取闪存;如果该映射关系不在SRAM内,那么它首先需要把映射关系从闪存里面读取出来,然后根据这个映射关系读取用户数据。这就意味着相比有DRAM的SSD,不带DRAM的SSD需要读取两次闪存才能把用户数据读取出来,读取性能和延时都要比带DRAM 的 SSD 差。
- 对顺序读来说,由于映射关系连续,一次映射块的加载就可以满足很多用户数据的读。这意味着DRAM-less的SSD也可以有好的顺序读性能。
- 对随机读来说,映射关系分散,一次映射关系的加载,可能只能满足几笔逻辑页的读,需要访问若干次闪存才能完成一次随机读操作,因此随机读性能就不是那么理想了。
- 管理带DRAM的SSD的映射表:相对简单一些,因为所有映射关系都可以缓存在大的DRAM里面,SSD固件可以快速获取和更新映射关系。
- 管理不带DRAM的SSD的映射表:不带DRAM的SSD只能是利用控制器上有限的 SRAM 资源来完成映射表管理。和大的DRAM相比,控制器上SRAM资源是非常有限的,不能容纳下整张映射表。一种常规管理思路是↓
- 设备运行时,所有映射关系都保存在闪存上面,按需加载映射关系到控制器SRAM,并把最近访问的映射关系缓存在控制器的 SRAM 中。
- 根据用户访问 SSD的时间和空间局部性,一部分映射表加载到SRAM中,因为接下来它们大概率会被再次使用到,因此映射表缓存对后续的访问是有帮助的。
-
🐇HMB
- 映射表除了可以放到板载DRAM、片上SRAM和闪存中,还可以放到主机的内存中。
- NVME 1.2及后续版本有一个重要的功能——HMB(Host Memory Buffer),就是主机在内存中专门划出一部分空间供SSD使用,SSD可以把它当成自己的DRAM使用,因此,映射表完全可以放到主机端的内存中。
该内存在物理上可以不连续,SSD不仅可以用它来存放映射表,还可以用它来缓存用户数据,具体怎么用,取决于SSD设计者。
| 优势 | 劣势 | |
|---|---|---|
| 带DRAM的SSD | 性能好,映射表完全可以放在DRAM中,查找和更新迅速 | 由于增加了一个DRAM,所以提高了SSD的成本,还有就是加大了SSD功耗 |
| DRAM-less的 SSD | 成本和功耗相对低 | 性能差 |
- 在性能上,HMB应该介于带DRAM(板载)和不带DRAM(映射表绝大多数存放在闪存)之间,因为SSD访问主机端DRAM的速度肯定比访问本地SSD端DRAM的速度要慢,但还是比访问闪存的速度(几十微秒)要快。
- HMB的出现为SSD的设计提供了新的思路。SSD可以自已不带DRAM,完全用主机DRAM来缓存数据和映射表。拿随机读来说:
- DRAM-less SSD访问映射表的时间是读闪存的时间;
- 带DRAM的SSD访问映射表的时间是读DRAM的时间;
- 而对HMB SSD来说,它访问映射表的时间是访问主机DRAM的时间,这接近DRAM SSD的性能,远远好于DRAM-less SSD。
🐇映射表写入
- 在SSD掉电前,需要把映射表写入闪存中。下次上电初始化时,需要把它从闪存中全部或者部分加载到SSD的缓存(DRAM或者SRAM)中。
- 随着SSD的写入,缓存中的映射表不断增加新的映射关系,为防止异常掉电导致这些新的映射关系丢失,SSD的固件不仅在正常掉电前把这些映射关系写入到闪存中,还在SSD运行过程中按照一定策略把映射表写入内存。这样即使发生异常掉电,丢失的也是一小部分映射关系,上电时可以较快地重建这些映射关系。
- 触发映射表写入的一般情况:
- 新产生的映射关系累积到一定阈值;
- 用户写入的数据量达到一定的阈值;
- 用户写完一个闪存块;
- 其他。
- 写入策略一般有全部更新和增量更新。
- 全部更新的意思是缓存中映射表(干净的和不干净的)全部写人闪存;
- 增量更新的意思是只把新产生的(不干净的)映射关系刷入闪存中。
- 显然,相比后者,前者需要写入更多的数据量,这一方面影响用户写入性能和延时;另一方面会增加写放大。全部更新的好处是固件实现简单,不需要知道哪些映射关系是干净的,哪些是不干净的。
- 固件算法在决策的时候,应根据软硬件架构进行综合考虑,使用最适合自己系统的映射表写入策略。
- 参考书籍:《深入浅出SSD:固态存储核心技术、原理与实战》(第2版)